ERNIE-Image-Turbo 8B: Comprehensive Multi-Model Comparison with Prompt Examples
Baidu has just open-sourced an 8B-parameter text-to-image model called ERNIE-Image. When comparing text-to-image models, we always instinctively compare parameter counts. Parameter count doesn't directly demonstrate a model's capabilities and strengths, but we still believe that "size matters" — parameter count represents potential, while real capability depends on training quality. This article makes no objective judgments; we let the benchmarks speak.
Open-Source Text-to-Image Model Parameter Rankings

Here's a ranking of open-source text-to-image models as of today, sorted by parameter count:
- HunyuanImage-3.0 (Tencent Hunyuan) — 80B total parameters (MoE, 64 experts, ~13B active): Currently the largest open-source T2I MoE model, native multimodal autoregressive architecture, excels at complex prompts, world knowledge reasoning, Chinese/English text rendering and knowledge-dense generation. Suitable for high-quality, professional scenarios, but inference requires high-end hardware (datacenter-grade, quantizable). Open-sourced September 2025, weights available on HuggingFace.
- FLUX.2 [dev] (Black Forest Labs) — 32B parameters: The open-source version of the FLUX.2 series, supporting T2I, image editing, and multi-reference image fusion. Rectified flow transformer architecture with exceptional prompt following, detail and coherence. Runs on consumer GPUs (with quantization/FP8 optimization), one of the 2026 open-source flagships.
- FLUX.1 [dev/schnell] — ~12B parameters: (Early FLUX.1 series) Classic DiT/flow matching model with top-tier prompt following and text rendering. Schnell is the distilled fast version. Largest community ecosystem, comprehensive ComfyUI support.
- Stable Diffusion 3.5 Large (Stability AI) — 8.1B parameters (MMDiT): SD series latest main model, significantly improved prompt following and layout, supports 1MP+ resolution. Medium variant at 2.5B parameters is more suitable for consumer hardware. Largest open-source community, mature LoRA/fine-tuning ecosystem.
- Qwen-Image / Qwen-Image-2.0 (Alibaba Qwen) — ~7B–20B parameters: (2.0 unified to ~7B, lightweight and efficient) Strong Chinese/multilingual text rendering, professional layout (supports 1K token long prompts), native 2K resolution. Version 2.0 unifies generation + editing with high efficiency, ideal for Asian languages and infographics.
- Z-Image-Turbo / Other compact efficient models — ~6B parameters: Efficient real-time/edge deployment models, fast speed, suitable for low-resource environments.
So in terms of parameter count, Baidu's ERNIE-Image is actually not that large — it sits in the middle. As for image performance, let the pictures speak.
ERNIE-Image Overview
ERNIE-Image is an open text-to-image model developed by Baidu's ERNIE-Image team. It is based on a single-stream diffusion transformer (DiT) with 8B parameters, using a latent diffusion model (LDM) framework, equipped with a lightweight prompt enhancer that expands brief inputs into richer, more structured prompts, better unlocking model capabilities. With just 8B DiT parameters, ERNIE-Image achieves state-of-the-art performance among open-weight text-to-image models — it focuses not just on visual appeal but on controllability: accurate content representation matters as much as aesthetics. In practice, it excels at complex instruction following, precise text rendering, and structured image generation — areas where many existing open-weight models still fall short.

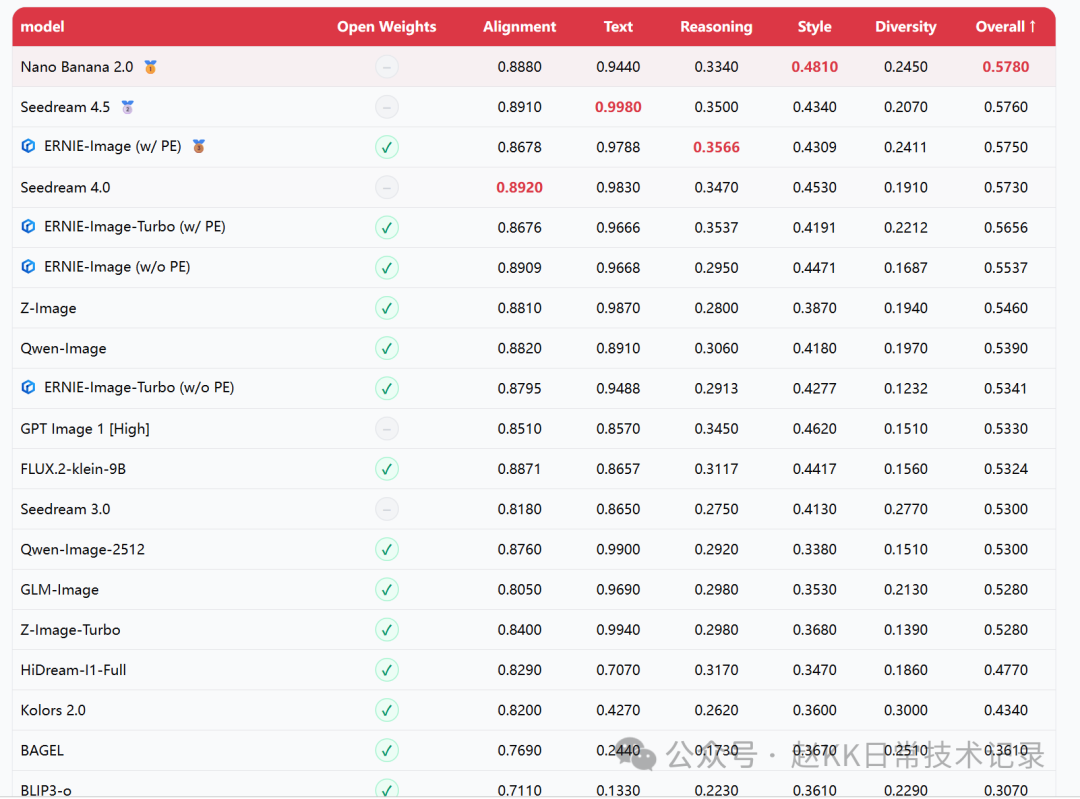
Model Benchmark Comparisons (Official)

Built-in Prompt Enhancement
ERNIE-Image performs best with long, detailed and well-structured prompts — richer descriptions generally yield better generation quality, tighter instruction fidelity, and more faithful rendering of complex layouts or narrative content. But in practice, users tend to enter short sentences rather than the detailed prompts that play to the model's strengths.
To bridge this gap, we released a built-in 3B prompt enhancer that expands brief user inputs into more detailed, structured prompts better suited for ERNIE-Image. The goal isn't to change user intent but to transform concise requests into a form that better leverages the model's value — especially in posters, anime, web layouts, game screenshots and other structured visual tasks.
The examples below illustrate this effect. Without prompt enhancement, the model tends to interpret short prompts literally and incompletely. With our 3B enhancer, prompts become more descriptive and structured, significantly improving results in many scenarios. We've also found that stronger large language models can push this further — suggesting that prompt enhancement is a practical lever for leveraging ERNIE-Image's long-prompt generation capability.



Replicating Official Prompts
Online demo: https://huggingface.co/spaces/baidu/ERNIE-Image-Turbo

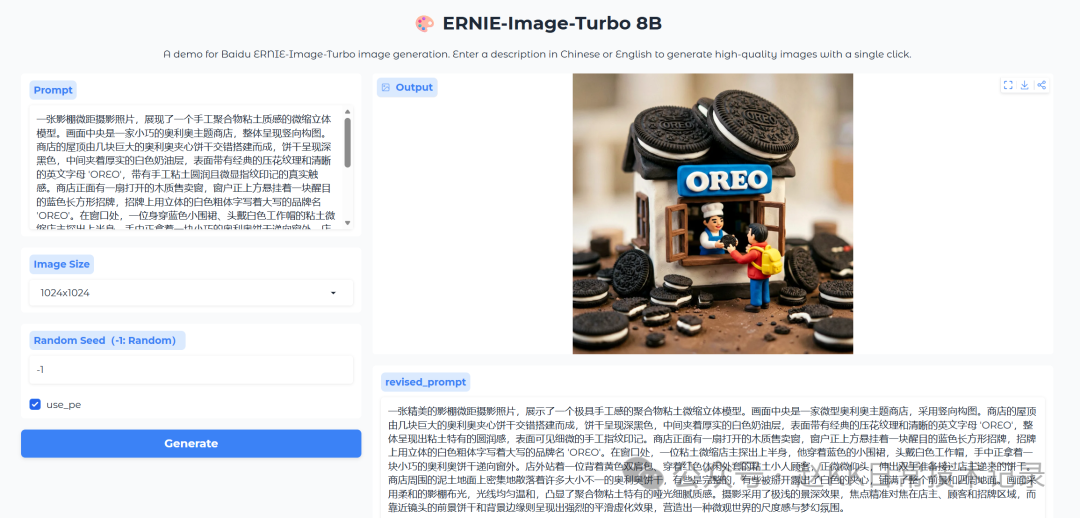
Prompt Practice: OREO Polymer Clay Miniature
This prompt is quite complex:


Full prompt:
A studio macro photography shot of a handcrafted polymer clay-textured miniature diorama. Centered in the frame is a small Oreo-themed shop in vertical composition. The roof is built from several giant Oreo cookies arranged in a cross pattern — deep black with thick white cream layers, classic embossed texture and clear 'OREO' lettering, with handmade clay rounded texture and subtle fingerprint details. The shop front has an open wooden serving window, above which hangs a prominent blue rectangular sign with bold 3D white uppercase letters reading 'OREO'. At the window, a tiny clay shopkeeper in a blue apron and white work cap leans forward, holding a small Oreo cookie to hand out the window. Outside stands a customer — a miniature clay figure wearing a yellow backpack and red casual jacket, looking up slightly with both hands extended to receive the cookie. The muddy ground around the shop is densely scattered with Oreos of various sizes — some intact, some broken open revealing white filling, covering the entire foreground and surrounding area. The scene uses soft studio lighting, even and warm, highlighting the matte细腻 texture of polymer clay. Extremely shallow depth of field with precise focus on the shopkeeper, customer and sign area, while foreground cookies and background edges show strong smooth bokeh, creating a perfect miniature-world scale and dreamy atmosphere.
Baidu ERNIE-Image Replication


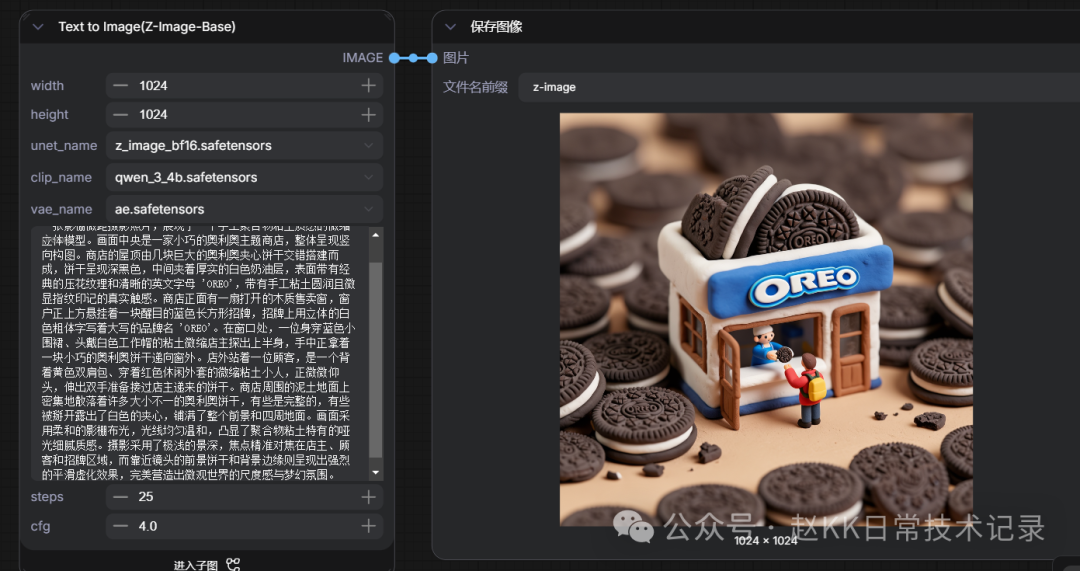
Z-Image Replication

FireRed Qwen-image-2512
FLUX2

Nanobana 2 Pro

Jimeng (即梦)


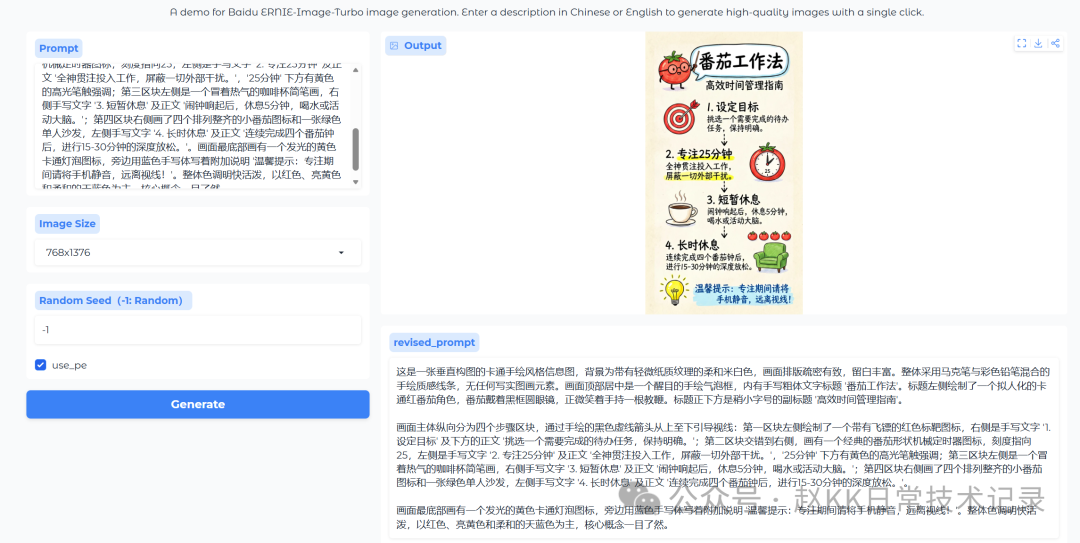
Multi-Text Combination Test
Prompt:
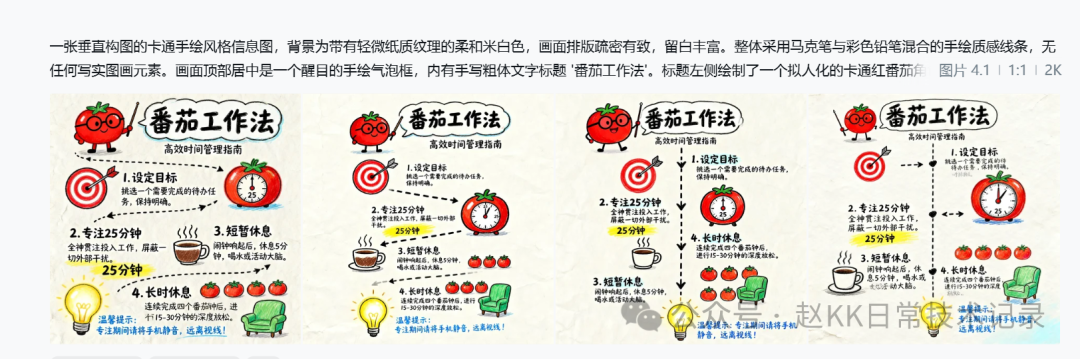
A vertically composed cartoon hand-drawn style infographic on soft beige-white background with subtle paper texture, well-spaced layout with generous whitespace. Overall uses marker pen and colored pencil mixed hand-drawn texture lines, no photorealistic elements. Centered at the top is a prominent hand-drawn speech bubble containing handwritten bold title text 'Pomodoro Technique'. To the left of the title is an anthropomorphic cartoon red tomato character wearing round black-framed glasses, smiling while holding a pointer. Directly below the title is a smaller subtitle 'Efficient Time Management Guide'. The main content is divided into four step blocks, connected by hand-drawn dashed black arrows from top to bottom: Block 1 shows a red target icon with dart on the left and handwritten text '1. Set Goals' with body text 'Pick one task to complete, keep it clear.' Block 2 alternates to the right with a classic tomato-shaped mechanical timer icon (set to 25), left text '2. Focus for 25 minutes' with body 'Work with full concentration, block all distractions.' and yellow highlight on '25 minutes'. Block 3 on the left has a steaming coffee cup sketch, right text '3. Short Break' with 'When alarm rings, rest 5 minutes, drink water or stretch.' Block 4 on the right shows four neatly arranged small tomato icons and green single sofa, left text '4. Long Break' with 'After completing four Pomodoro cycles, take 15-30 minute deep relaxation.' At the bottom is a glowing yellow cartoon light bulb icon with blue handwritten note 'Tip: During focus periods, silence your phone and keep it out of sight!' Bright and cheerful color scheme dominated by red, bright yellow and soft sky blue.
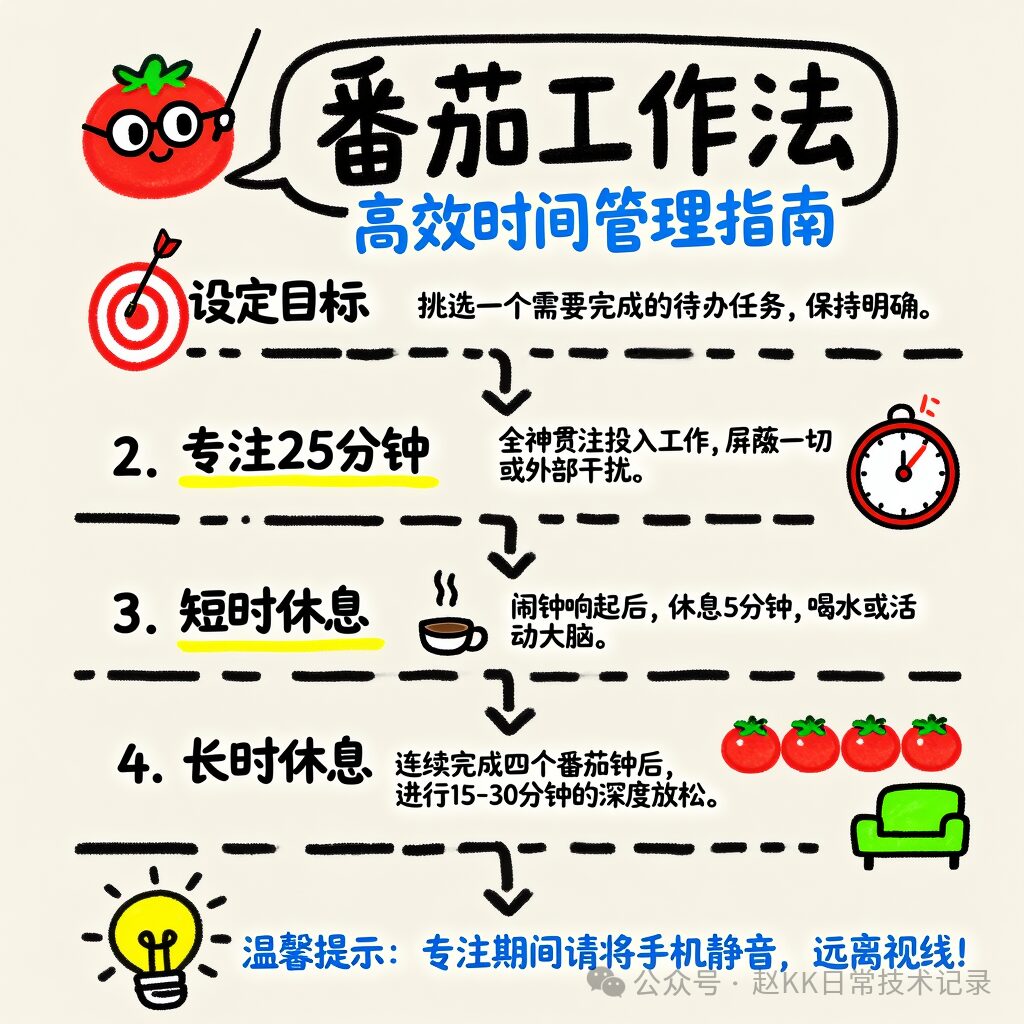
Official Result
Baidu ERNIE-Image Replication


Z-Image

FireRed Qwen-image-2512
FLUX2
Chinese support is poor, result is in English:

Nanobana 2 Pro

Jimeng (即梦)


Portrait Performance
Prompt:
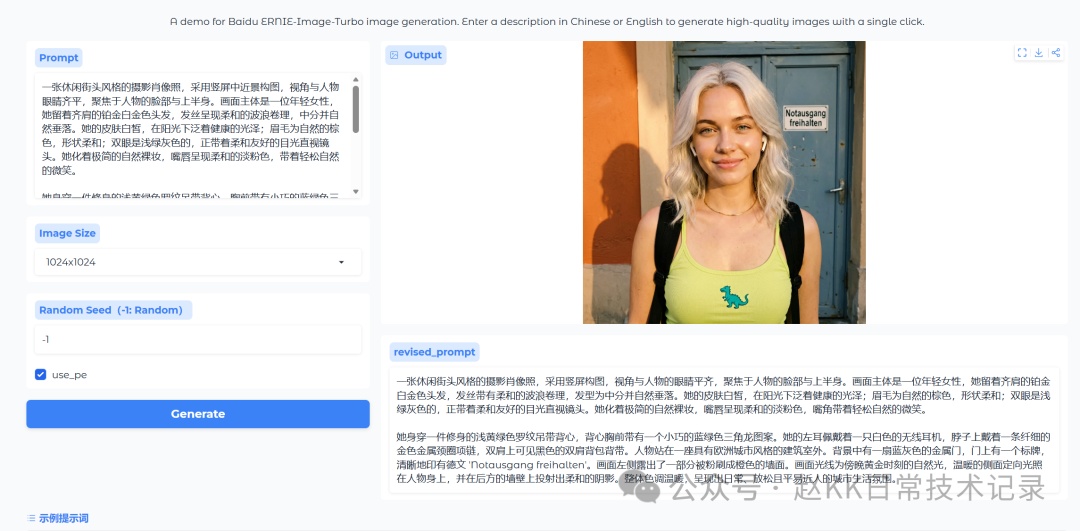
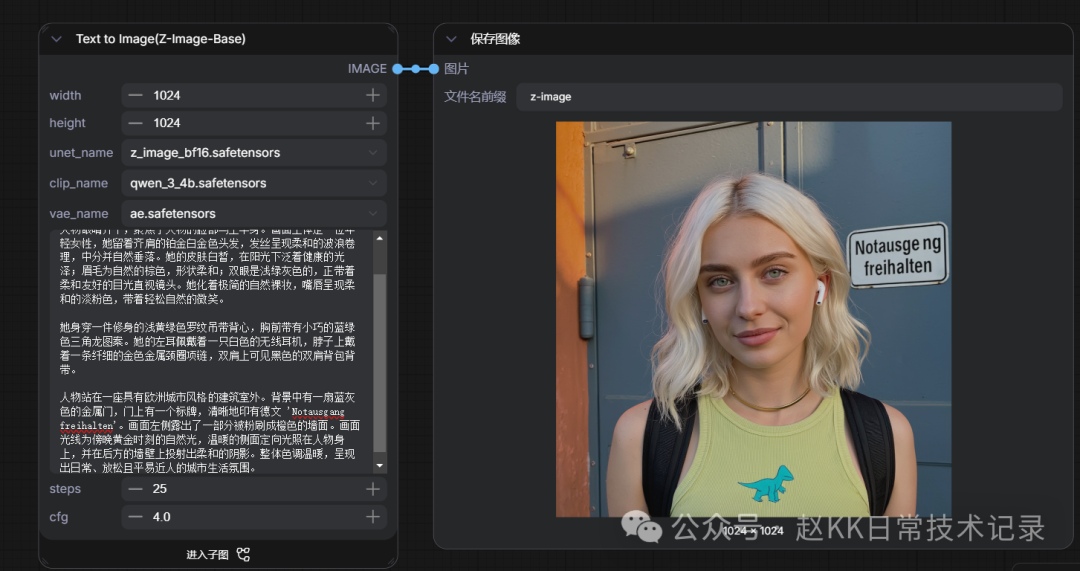
A casual street-style photographic portrait in vertical medium close-up composition, eye-level angle focusing on the person's face and upper body. The subject is a young woman with shoulder-length titanium platinum blonde hair in soft waves, center-parted and naturally falling. Her skin is fair with a healthy glow in sunlight; eyebrows are natural brown and softly shaped; eyes are light gray-green, looking directly at the camera with a gentle, friendly gaze. She wears minimal natural nude makeup with soft pink lips and a relaxed, natural smile. She's wearing a fitted pale yellow-green ribbed tank top with a small blue-green triangle dinosaur design on the chest. A white wireless earbud is visible in her left ear, a thin gold metal circle necklace around her neck, and black backpack straps visible over her shoulders. The person stands outdoors in front of a European-style building. In the background is a blue-gray metal door with a sign clearly printing German text 'Notausgang freihalten'. To the left, part of an orange-painted wall is visible. Lighting is golden hour natural light — warm directional side light hits the subject and casts soft shadows on the wall behind. Overall warm tones conveying a daily, relaxed and approachable urban lifestyle atmosphere.
Official Result

Baidu ERNIE-Image Replication


Z-Image

FireRed Qwen-image-2512

FLUX2

Nanobana 2 Pro

Jimeng (即梦)


Portrait 2 — Hyper-Realistic Style
Prompt:
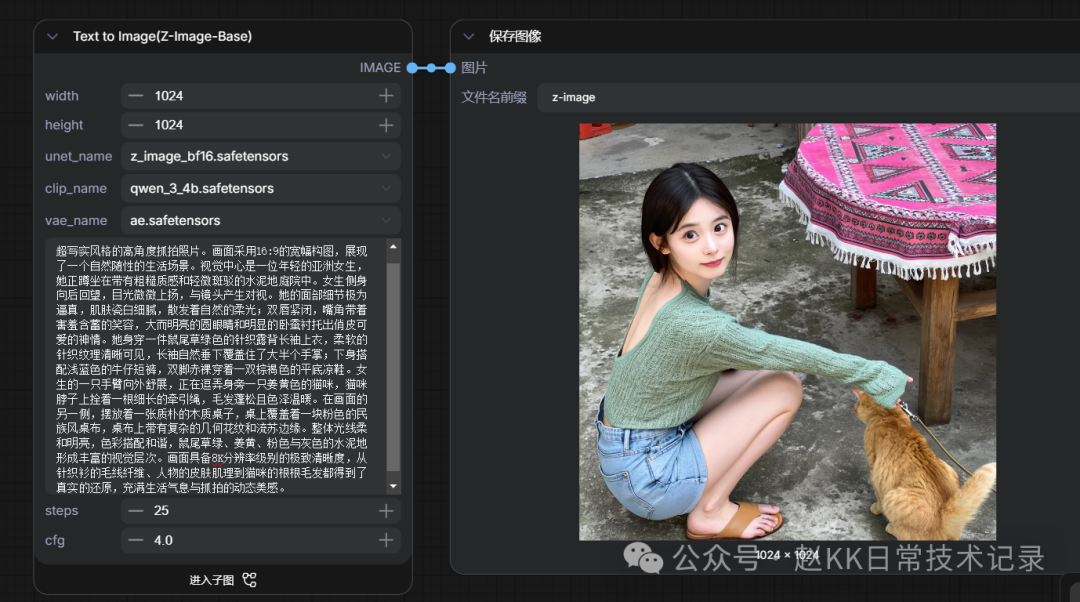
Hyper-realistic high-angle candid shot. 16:9 wide composition showing a casual natural living scene. Visual center is a young Asian girl crouching on a rough-textured, slightly mottled concrete courtyard floor. She turns sideways to look back, gaze slightly upward, making eye contact with the camera. Her facial details are extremely realistic — porcelain-white delicate skin with natural soft glow; lips closed with a shy, subtle smile; large bright round eyes with visible aegyo sal conveying a playful, cute expression. She wears a sage green knit backless long-sleeve top — soft knit texture clearly visible, long sleeves naturally falling to cover most of her palms; light blue denim shorts below; barefoot in brown flat sandals. One arm extended outward, teasing a tortoiseshell cat beside her — the cat wears a thin leash, fluffy warm-toned fur. On the other side sits a rustic wooden table covered with a pink ethnic-style tablecloth featuring complex geometric patterns and fringed edges. Soft, bright overall lighting with harmonious color palette — sage green, tortoiseshell brown, pink and gray concrete creating rich visual layers.
Official Result

Baidu ERNIE-Image Replication

Z-Image


FireRed Qwen-image-2512

All tests in this article were conducted using official or publicly reproducible configurations for each model. The prompt enhancement feature is built into ERNIE-Image; other model comparisons did not use additional prompt enhancement.