Baidu Open-Sources ERNIE-Image-Turbo 8B: The Most Comprehensive Multi-Image Side-by-Side Comparison Online + the “Make Anything Eat West Lake Vinegar Fish” Prompt
Just moments ago, Baidu open-sourced ERNIE-Image, an 8B-parameter text-to-image model. When comparing text-to-image models, people still tend to look at parameter count first. Of course, parameter count cannot directly show a model’s actual strengths or specialties, but many people still default to the idea that “bigger is better.” In reality, parameters only represent potential. Real capability still depends on training quality, and I’ll leave the final judgment to the evaluation results below.

Article cover image
First, here is a list of open-source text-to-image models available as of today, ranked by parameter count. You may not have heard much about the first one:
- HunyuanImage-3.0 (Tencent Hunyuan) — 80B total parameters (MoE, 64 experts, ~13B active): Currently the largest open-source T2I MoE model, with a native multimodal autoregressive architecture. It is strong at complex prompts, world-knowledge reasoning, Chinese and English text rendering, and knowledge-intensive generation. Suitable for high-quality professional scenarios, but inference requires high-end hardware.
- FLUX.2 [dev] (Black Forest Labs) — 32B parameters: Supports T2I, image editing, and multi-reference image fusion. Extremely strong in prompt following, detail, and coherence, and can run on consumer GPUs with quantization optimizations.
- FLUX.1 [dev/schnell] — ~12B parameters: A classic DiT / flow matching model with top-tier prompt following and text rendering, plus a mature community ecosystem.
- Stable Diffusion 3.5 Large (Stability AI) — 8.1B parameters (MMDiT): Significantly improved prompt following and layout capabilities, with support for higher resolutions; the Medium variant is 2.5B.
- Qwen-Image / Qwen-Image-2.0 (Alibaba Qwen) — ~7B–20B parameters: Strong Chinese / multilingual text rendering and professional layout generation, making it suitable for Asian-language use cases and infographics.
- Z-Image-Turbo / other small efficient models — ~6B parameters: Focused more on efficient real-time / edge deployment, suitable for low-resource environments.
So in terms of parameter count, Baidu’s ERNIE-Image is not especially large. It sits somewhere in the middle. As for image quality, let’s just look at the results.
ERNIE-Image
ERNIE-Image is an open text-to-image model developed by Baidu’s ERNIE-Image team. It is based on a single-stream Diffusion Transformer (DiT), uses 8B parameters and a latent diffusion (LDM) framework, and comes with a lightweight prompt enhancer that expands short inputs into richer, more structured prompts to better unlock the model’s capabilities. According to the article, the model emphasizes not only visual appeal but also controllability, especially in complex instruction following, precise text rendering, and structured image generation.

ERNIE-Image overview
Official cross-model comparison
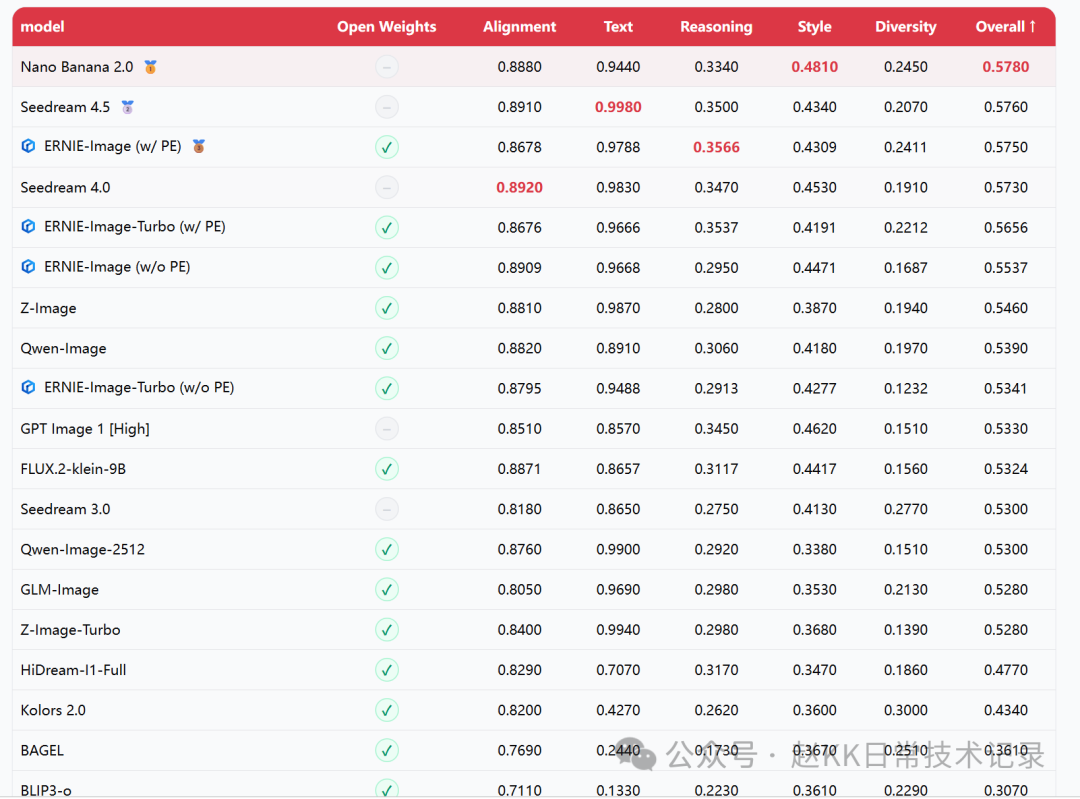
Cross-model comparison image
The model also adds prompt enhancement
ERNIE-Image performs best with long, detailed, and well-structured prompts. Richer descriptions usually lead to better generation quality, tighter instruction fidelity, and more faithful rendering of complex layouts or narrative content. In practice, however, users usually enter only short sentences.
To bridge that gap, Baidu released a built-in 3B prompt enhancer that expands short user inputs into more detailed, more structured prompts better suited to ERNIE-Image, especially for posters, anime, web layouts, game screenshots, and other structured visual tasks.
The article argues that without prompt enhancement, the model often interprets short prompts too literally and incompletely. With the 3B prompt enhancer, prompts become more descriptive and more structured, producing significantly better results in many scenarios.
First, recreate the results using the official website prompts
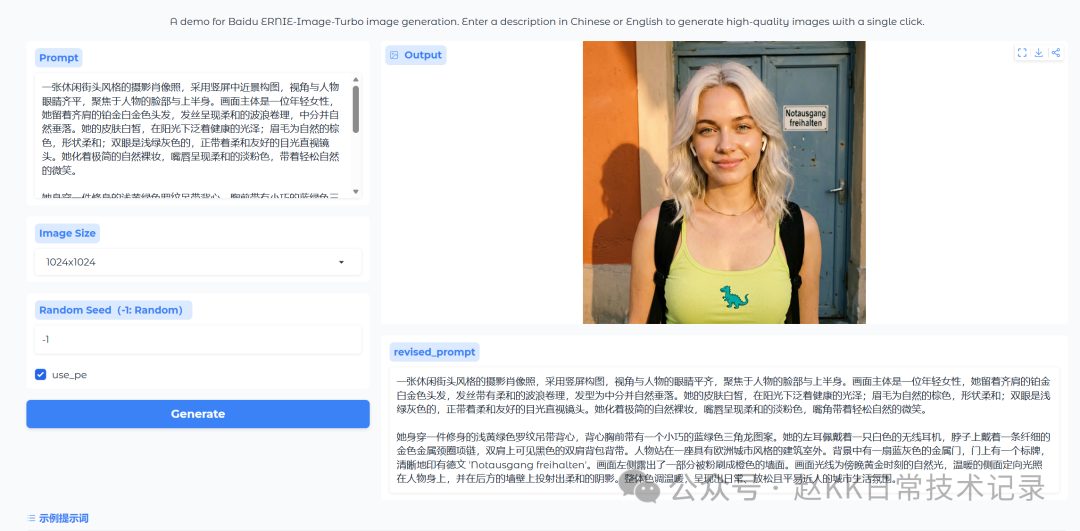
Online demo: https://huggingface.co/spaces/baidu/ERNIE-Image-Turbo

Online demo page screenshot
Prompt
It has to be said: this prompt is really quite complex
A studio macro photograph,
showing a miniature three-dimensional model with a handmade polymer clay texture.
At the center of the image is a tiny Oreo-themed shop,
presented in a vertical composition. The roof of the shop is built from several giant Oreo sandwich cookies arranged in an interlocking structure.
The cookies are deep black, with a thick white cream filling in the middle,
and their surfaces feature the classic embossed texture and the clearly visible English letters 'OREO',
with the rounded handmade feel of clay and subtle fingerprint marks.
On the front of the shop is an open wooden sales window,
and directly above the window hangs a striking blue rectangular sign.
On the sign, the brand name 'OREO' is written in bold white three-dimensional uppercase letters.
At the window, a miniature clay shopkeeper wearing a blue apron and a white work cap leans out with the upper half of the body,
holding a small Oreo cookie in hand and passing it out through the window. Outside the shop stands a customer,
a tiny clay figure wearing a red casual jacket and a yellow backpack, looking slightly upward,
reaching out with both hands to receive the cookie from the shopkeeper.
Scattered densely across the dirt ground around the shop are many Oreo cookies of different sizes.
Some are intact, while others are broken open to reveal the white cream filling,
covering the entire foreground and surrounding ground. The image uses soft studio lighting,
with even and gentle illumination that highlights the matte, delicate texture unique to polymer clay.
The photograph uses an extremely shallow depth of field, with precise focus on the shopkeeper, the customer, and the sign area,
while the cookies near the lens and the edges of the background show a strong, smooth blur,
perfectly creating the sense of scale of a microscopic world and a dreamy atmosphere.
Official Baidu ERNIE-Image results

Official result 1
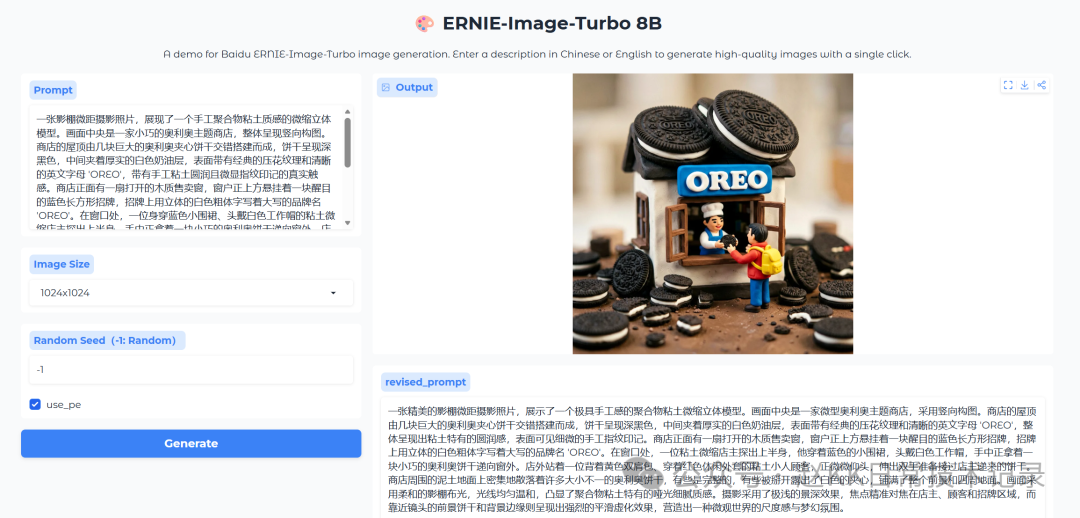
Official result 2
It can also be reproduced 100% in Chinese. Below are the comparison results from different models.
A vertically composed infographic in a cartoon hand-drawn style,
with a soft off-white background featuring a slight paper texture. The layout is well balanced,
with generous whitespace. The overall image uses hand-drawn lines with a mixed marker and colored-pencil texture,
with no realistic illustration elements at all. At the top center of the image is an eye-catching hand-drawn speech bubble frame,
containing the handwritten bold title '番茄工作法'.
To the left of the title is an anthropomorphic cartoon red tomato character,
wearing round black-framed glasses and smiling while holding a pointer.
Directly beneath the title is a slightly smaller subtitle: '高效时间管理指南'.
The main body of the image is vertically divided into four step sections, guided from top to bottom by hand-drawn black dashed arrows:
In the first section, the left side shows a red target icon with a dart,
and the right side contains the handwritten text '1. 设定目标' and the body text below it: '挑选一个需要完成的待办任务,保持明确。';
The second section alternates to the right side, showing a classic tomato-shaped mechanical timer icon with the dial pointing to 25,
while the left side contains the handwritten text '2. 专注25分钟' and the body text '全神贯注投入工作,屏蔽一切外部干扰。';
In the third section, the left side shows a simple sketch of a steaming coffee cup, and the right side contains the handwritten text '3. 短暂休息' and the body text '闹钟响起后,休息5分钟,喝水或活动大脑。';
In the fourth section, the right side shows four neatly arranged small tomato icons and a green single-seat sofa, while the left side contains the handwritten text '4. 长时休息' and the body text '连续完成四个番茄钟后,进行15-30分钟的深度放松。'.
At the very bottom of the image is a glowing yellow cartoon light-bulb icon, next to which is a blue handwritten note: '温馨提示:专注期间请将手机静音,远离视线!'.
Below, the article continues with multiple groups of image comparisons, including “official result / Baidu ERNIE-Image reproduction / z-image / FireRed / Qwen-image-2512 / Flux2 / Nanobana 2 pro / Jimeng.”
Portrait performance
A casual street-style photographic portrait, using a vertical medium close-up composition, with the camera at eye level,
focusing on the subject’s face and upper body. The main subject is a young woman.
She has platinum-blonde shoulder-length hair, with soft wavy strands, parted in the middle and falling naturally.
Her skin is fair, glowing with a healthy sheen in the sunlight; her eyebrows are naturally brown and softly shaped;
her eyes are a light green-gray color, looking directly into the camera with a gentle and friendly gaze. She wears minimal, natural nude makeup,
and her lips are a soft pale pink, carrying a relaxed and natural smile.
She is wearing a fitted light yellow-green ribbed tank top, with a small teal triceratops graphic on the chest.
In her left ear she wears a white wireless earbud, and around her neck is a thin gold metal choker necklace.
Black backpack straps are visible over both shoulders.
The subject is standing outdoors beside architecture with a European city style. In the background there is a blue-gray metal door,
with a sign on it clearly printed with the German text 'Notausgang freihalten'.
On the left side of the frame, part of an orange-painted wall is visible.
The lighting is natural golden-hour evening light, with warm directional side light falling on the subject,
and casting a soft shadow on the wall behind her. The overall color tone is warm,
presenting an everyday, relaxed, and approachable urban-lifestyle atmosphere.
The article then presents a second portrait set and a series of long-prompt examples, followed by a summary of prompt-writing rules.
Prompt-writing rules
- ERNIE-Image (including SFT / Turbo) relies heavily on long, detailed, structured prompts.
- Long prompts are significantly better than short prompts. The model does not proactively fill in missing details or refine content on its own; short prompts tend to lead to overly literal interpretations.
- Common issues with short prompts: low output quality, messy layouts, text errors, and lack of narrative coherence.
- The official recommendation is to use Prompt Enhancer (PE). It can expand brief input into structured, detail-rich prompts.
- Language choice: Chinese first, though mixed Chinese-English or pure English also works; avoid vague descriptions.
- Structured writing framework: subject description → details and relationships → layout and composition → style and atmosphere → quality-boosting terms → negative prompts.
- Key techniques: maintain high information density, describe everything explicitly, make good use of Prompt Enhancer, and for text rendering, clearly specify the exact text content / font / position / color.
- Especially strong for structured scenes: posters, anime storyboards, multi-panel layouts, web UI, game interfaces, etc.
This is a high-definition ultra-realistic food photography and editorial infographic poster in a vertical composition (approximately 3:4 ratio)... (the original article contains an ultra-long food poster prompt; the core paragraph and matching images are preserved here)
A vertical multi-panel fashion lookbook collage poster using a grid layout, with a clean gray-white background... (the original article contains an ultra-long fashion poster prompt)
A high-quality digital illustration in a vertical composition. At the center of the image, the English word ‘ITALY’ is spelled out in bold uppercase letters stacked vertically in an irregular arrangement... (the original article contains an ultra-long food-letter poster prompt)
“Make anything eat food” recreation prompt
A real live-action shot, single take, complete first-person perspective, no editing, no angle switching, no scene switching, no montage, no flash cuts, no music, no subtitles. There are only two characters: my unseen first-person perspective and @Image1 sitting across from me. Only natural ambient sound: light restaurant noise, tableware sounds, distant water sounds, faint voices, chewing sounds, spitting sounds, rinsing sounds, and my laughter.
Location: an outdoor dining table beside West Lake in Hangzhou, near the water, in quiet daylight or soft evening light...
Action scene: @Image1 is sitting across from me, happily eating from a bowl and enjoying rice and other dishes, except there is no West Lake vinegar fish. From the first-person perspective, I pick up a bite of fish with chopsticks and feed it to her. She first accepts it happily, then reacts with exaggerated but believable disgust, turns her head, spits it out and rinses her mouth, and finally angrily throws the entire plate of fish into the nearby lake.
Ending: She angrily completes the throw and continues facing the lake, while the person behind the camera remains in first-person perspective and laughs.
Additional requirements: 1) video length 20 seconds, using seedance2.0; 2) real live-action shooting + smartphone-video realism; 3) 16:9 horizontal aspect ratio.
The article concludes that Baidu’s newly open-sourced text-to-image model is highly competitive overall, but to use it well, you need to follow its prompt-writing rules—especially its preference for long-form text descriptions.

Official result
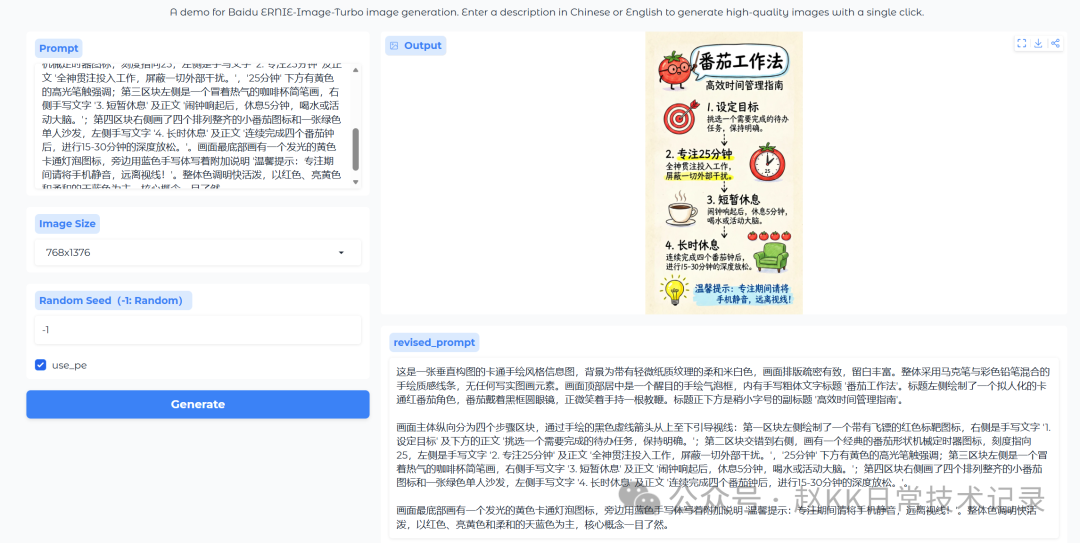
Baidu ERNIE-Image reproduction

Illustration 15
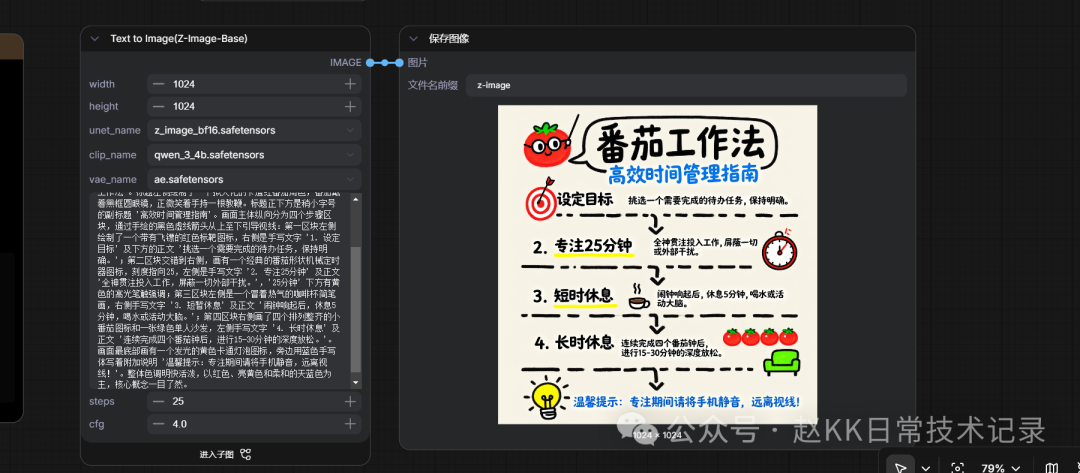
z-image
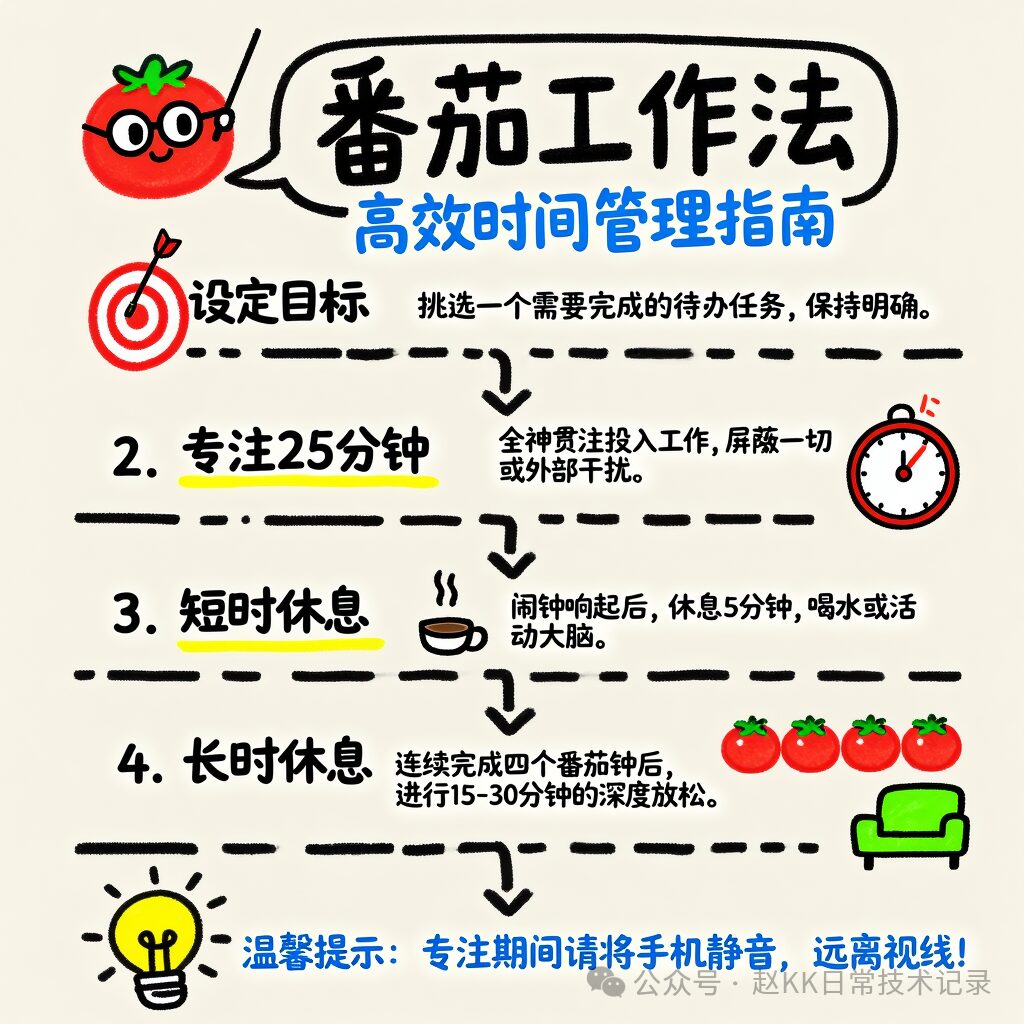
Illustration 17

FireRed

Qwen-image-2512

Flux2

Nanobana 2 pro
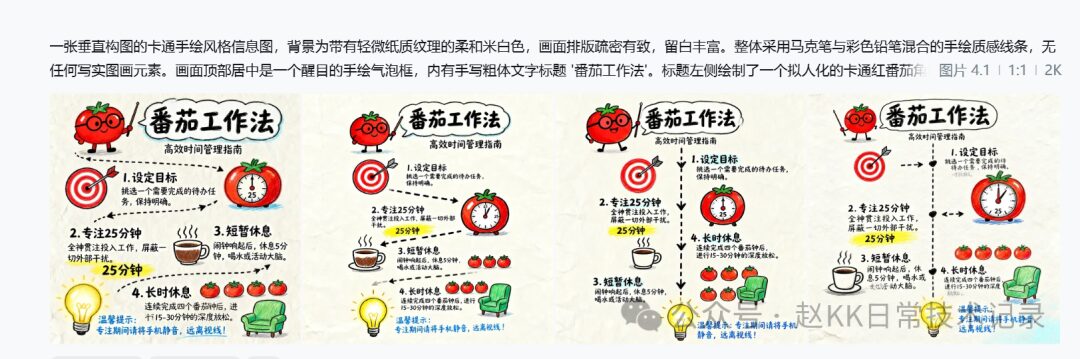
Jimeng

Illustration 23

Official result (portrait)
Baidu ERNIE-Image reproduction (portrait)

Illustration 26
z-image (portrait 2)

Illustration 28

FireRed (portrait 2)

Qwen-image-2512 (portrait 2)

Flux2 (portrait 2)

Nanobana 2 pro (portrait 2)

Jimeng (portrait 2)

Prompt-writing rules illustration 1

Prompt-writing rules illustration 2
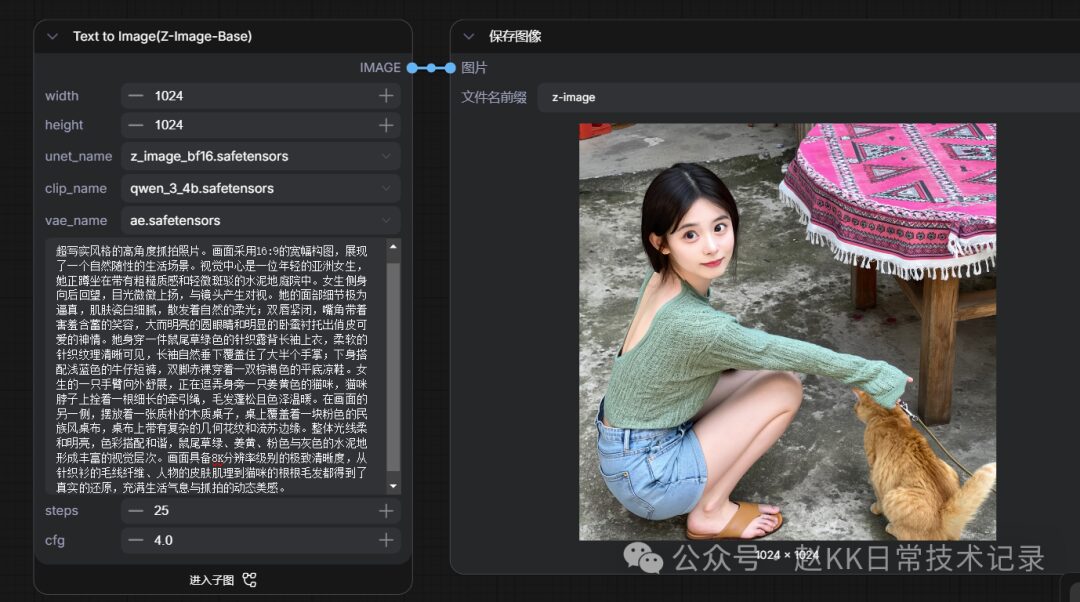
Prompt-writing rules illustration 3

Prompt-writing rules illustration 4

Prompt-writing rules illustration 5

Prompt-writing rules illustration 6

Prompt-writing rules illustration 7

Prompt-writing rules illustration 8

“Make anything eat food” recreation illustration 1
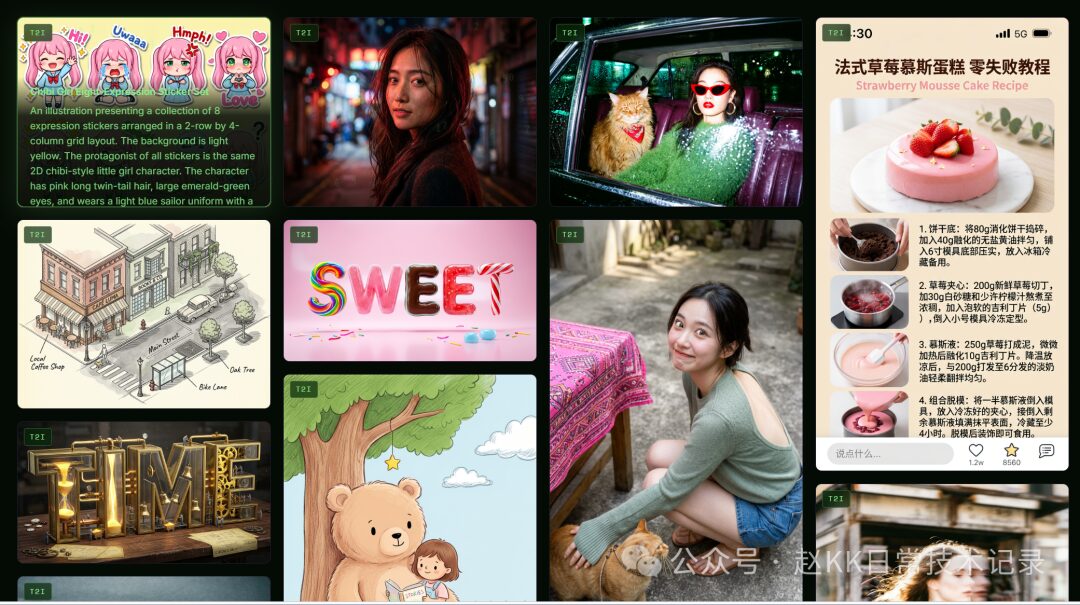
“Make anything eat food” recreation illustration 2

“Make anything eat food” recreation illustration 3

“Make anything eat food” recreation illustration 4

“Make anything eat food” recreation illustration 5

“Make anything eat food” recreation illustration 6